
The intelligence layer has emerged as the dominant architectural pattern for enterprise AI deployment. Instead of replacing enterprise systems (ERP, CRM, HRMS), an intelligence layer sits between them — reading data from multiple sources, applying AI-powered processing, and writing results back to existing systems.
This pattern works because it respects a fundamental reality of enterprise IT: you can't replace everything at once, and you shouldn't have to. The intelligence layer adds capability without requiring migration.
But not all intelligence layers are built equal. Here are the architectural patterns that separate durable, scalable intelligence layers from brittle prototypes.
Pattern 1: Ingestion Flexibility
The first architectural decision is how the intelligence layer receives data. Enterprise data arrives in many forms:
- API calls from modern systems
- File drops (CSV, XML, JSON) from batch processes
- Email attachments (PDF invoices, signed contracts)
- Scanned documents (paper that's been digitised)
- Database extracts from legacy systems
- Webhook events from SaaS applications
A durable intelligence layer handles all of these through a unified ingestion layer that normalises data regardless of source. Each connector converts the source format into a standard internal representation that downstream processing can consume.
The key principle: adding a new data source should require a new connector, not changes to the processing logic. This separation of concerns is what allows the system to scale to new use cases without rearchitecting.
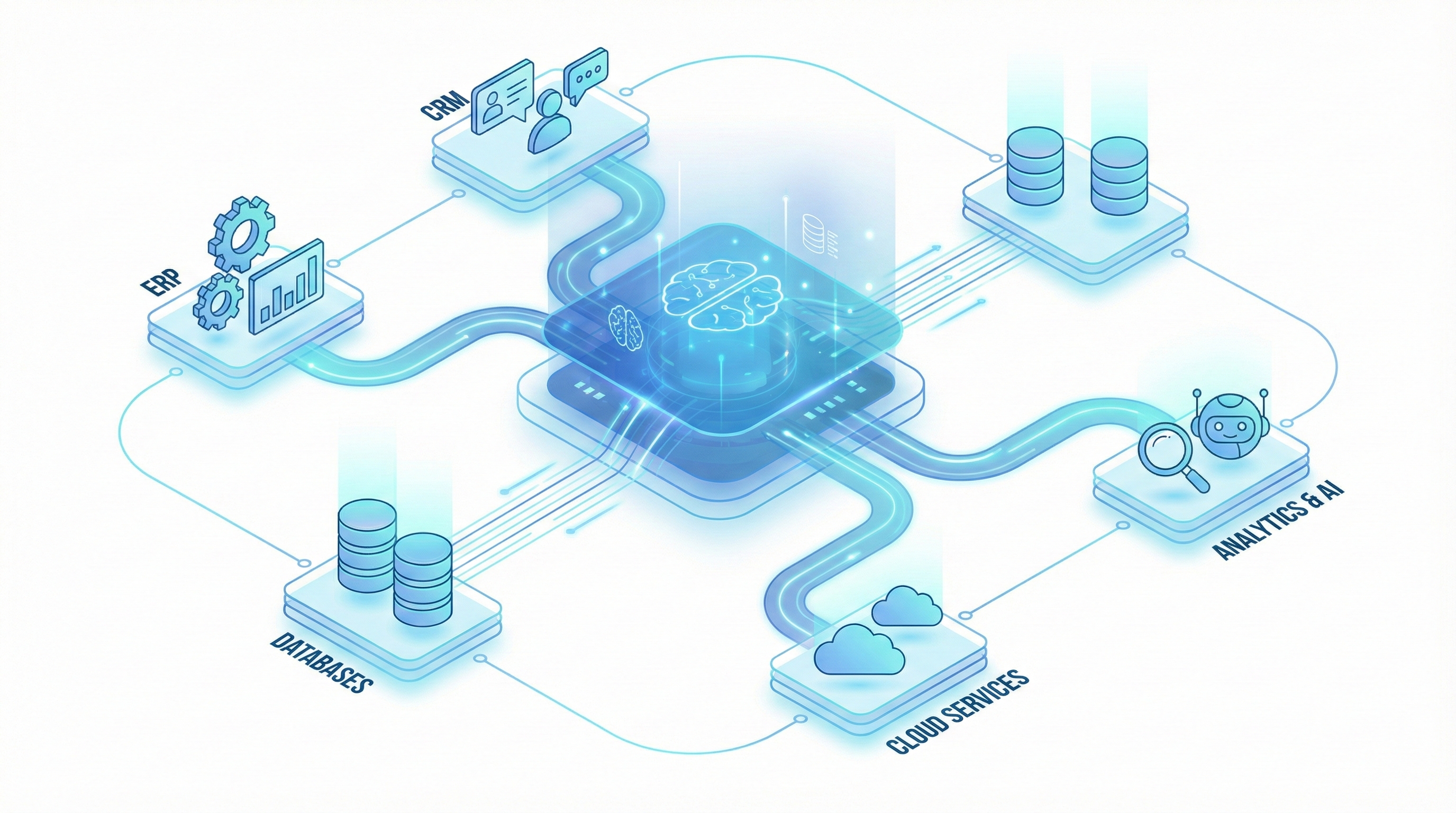
Pattern 2: Processing Pipeline Architecture
Once data is ingested, it flows through a processing pipeline. The pipeline architecture matters because it determines how easy the system is to modify, debug, and extend.
The recommended pattern is a series of discrete, composable processing steps:
- Classification: What type of input is this?
- Extraction: What are the key data elements?
- Enrichment: What additional context is needed? (Master data lookup, regulatory rules, historical data)
- Validation: Does the data make sense? (Business rules, cross-document checks, compliance rules)
- Decision: What should happen next? (Approve, reject, escalate, route)
- Action: Execute the decision (update system, notify person, trigger workflow)
Each step produces a defined output and logs its inputs, outputs, and confidence scores. This makes the pipeline observable, auditable, and debuggable.
The anti-pattern: a monolithic processing function that takes raw input and produces final output in one step. This works for demos but fails in production, where you need to understand where errors occur and adjust individual processing steps without affecting others.
Pattern 3: Confidence-Based Routing
Not every input can be processed automatically with sufficient confidence. The intelligence layer needs a systematic approach to handling uncertainty.
The pattern: every processing step produces a confidence score along with its output. When confidence falls below a defined threshold, the item is routed to human review — with all the context needed for a quick decision.
This creates three processing lanes:
- High confidence → automatic processing: The system handles it end-to-end
- Medium confidence → assisted processing: The system does the work but flags it for human review
- Low confidence → manual processing: The system provides what context it can and routes to a human
The thresholds are configurable per processing step, per document type, and per client — because acceptable risk levels vary. A bank's KYC process may have tighter thresholds than a manufacturer's invoice process.
Pattern 4: Feedback Loops
The intelligence layer should get smarter over time. This requires feedback loops:
- When a human corrects an extraction error, the correction feeds back to improve future extraction
- When an exception is resolved, the resolution pattern can be encoded as a new rule
- When a new document format appears, it's captured for model training
The feedback loop architecture means the system's accuracy improves with use — each processed item makes the system slightly better at processing the next one.

Pattern 5: Multi-Tenant Design
Even for single-client deployments, building with multi-tenant principles pays off:
- Configuration-driven behaviour: Business rules, thresholds, routing logic, and report formats are configuration, not code
- Data isolation: Each business unit or entity's data is logically separated
- Independent scaling: Processing capacity can be allocated based on volume
This pattern enables the intelligence layer to expand across business units, subsidiaries, and markets without re-engineering.
Pattern 6: Observability
An intelligence layer that can't be observed can't be trusted. Build in:
- Processing dashboards: Volumes, throughput, accuracy rates, exception rates — in real time
- Audit trails: Every input, every processing step, every output — logged with timestamps and actor information
- Alerting: When processing accuracy drops, volumes spike, or exceptions accumulate, the right people know immediately
Observability isn't a nice-to-have. It's what makes the difference between a system the operations team trusts and one they work around.
The Result
When these patterns are implemented well, the intelligence layer becomes an operational backbone that:
- Handles increasing volume without proportional cost increase
- Adapts to new document types, business rules, and markets through configuration
- Improves accuracy over time through feedback loops
- Provides operational intelligence through the structured data it processes
- Maintains complete audit trails for compliance and governance
This is what separates an intelligence layer from a point solution. Point solutions solve one problem. Intelligence layers solve a class of problems — and get better at it over time.